Selenium을 이용한 웹사이트 크롤링
참고
설치
-
Window 환경에서 테스트한다
-
3.7.9 사용
-
pip까지 모두 한꺼번에 설치
-
virtualenv 설치
|
pip install virtualenv |
-
이유를 모르겠지만 Python 3 윈도우 설치 버전에서는 virtualenv.exe가 만들어지지 않아
-
다음과 같이 스크립트 생성
-
cmd.exe를 관리자 권한으로 실행 (또는 PATH에 걸려 있는 아무 디렉토리에서)
|
cd C:\Program Files\Python37\Scripts |
-
virtualenv로 환경을 생성
|
cd selenium |
-
Selenium 설치
|
pip install selenium |
-
Chrome 브라우저 Web Driver 설치
-
https://sites.google.com/a/chromium.org/chromedriver/downloads
-
구글 크롬 버전에 따라 맞는 버전 설치

테스트
-
다운 받은 크롬 브라우저 Web Driver를 Python의 Scripts(예: C:\Program Files\Python37\Scripts)로 복사
-
다음과 같은 테스트 프로그램 실행
|
import selenium |
|
python selenium_test.py |
-
다음과 같이 브라우저가 기동 된다.

-
네이버 로그인이 필요하면 다음과 같이 실행한다.
|
from selenium import webdriver |
브라우저를 백그라운드로 띄우려면
-
다음과 같이 headless 옵션을 준다
|
# 옵션 생성 |
본격적으로 브라우저를 제어해 보자
-
여기서 시나리오는 네이버 단어장의 모든 단어를 읽어 오는 것이다
-
다음과 같이 네이버 사전으로 이동한다.
|
time.sleep(2) |
-
다음과 같은 브라우저 화면이 있다고 가정할 때 ‘전체'에 해당하는 부분을 클릭하고자 한다.
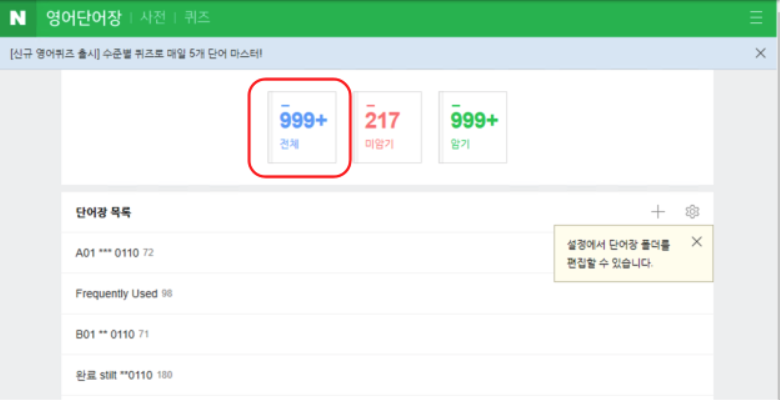
-
브라우저의 개발자 도구를 연다
-
Elements에서 태그들을 확장하다 보면 아래와 같이 해당 부분이 하이라이트 되는 부분을 찾을 수 있다.
-
오른쪽 버튼을 누른 후 Copy ⇒ Copy Xpath 를 선택한다.
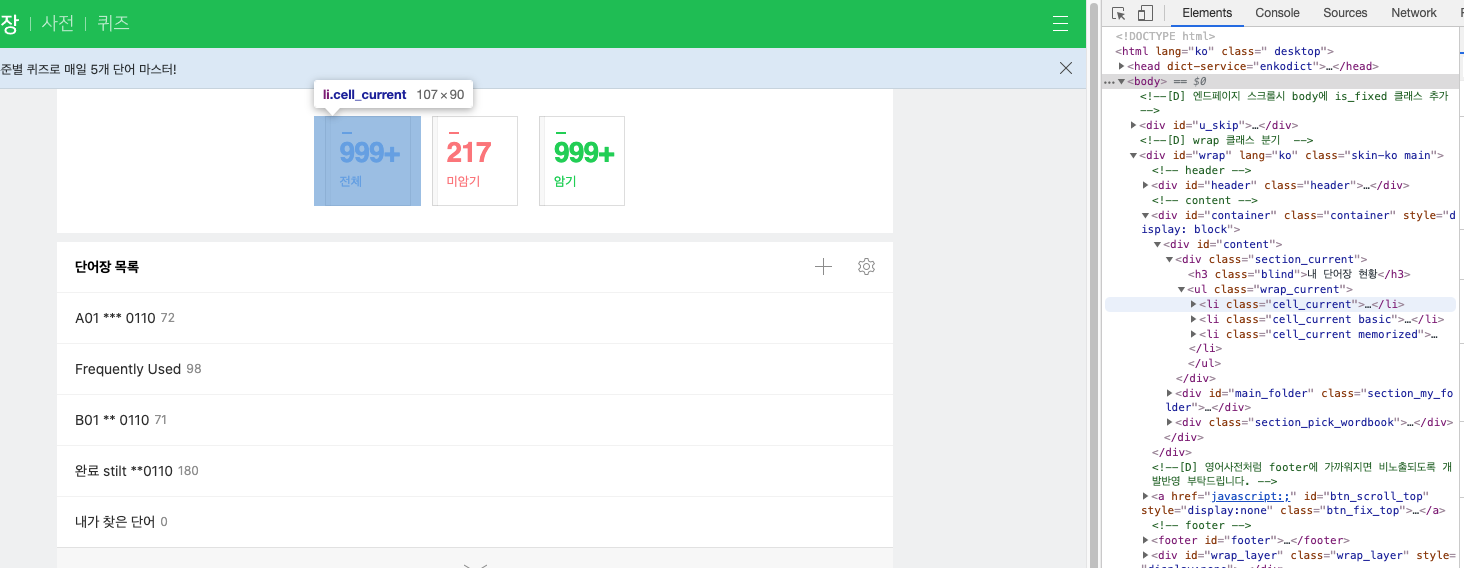
-
그리고 해당 부분을 이용해서 다음과 같이 클릭 하도록 한다.
|
time.sleep(1) |
-
만약 목록(여기서는 ‘단어장 목록'을 제어해야 한다면, 다음과 같이 배열과 for 문을 사용한다.
-
다음 구문은 단어장에 해당하는 main_folder를 구한 후에 그 안에 있는 <ul>, <li> 태그를 구한다.
-
실제 Python의 for 문은 0부터 시작하지만, xpath를 통한 태그 indexing은 1부터 시작하므로 i+1을 했다.
-
여기서는 단어장 클릭을 통해 페이지를 변경했다가, 다시 이전 페이지로 돌아오는 작업을 하기 때문에 for 문 안에서 매번 다시 driver.find_xxx 로 태그를 구하고 있다.
-
find_element_xxx 는 하나의 태그를, find_elements_xxx 는 해당 조건에 해당하는 여러 개의 태그들을 배열로 가져오는 역할을 한다.
|
list = driver.find_element_by_xpath('//*[@id="main_folder"]/ul') |
찾으려는 태그가 존재하지 않으면
-
브라우저의 컨텐츠에 따라 원하는 태그가 존재하지 않을 수도 있다.
-
그러면 에러가 발생하므로, 아래와 같이 존재하는지 체크해서 작업을 하게 할 수도 있다.
|
if len(driver.find_elements_by_xpath('//*[@id="btn_more_folder"]')) > 0: |
부모 엘리먼트 선택
-
아래에서 span을 기준으로 엘리먼트를 선택한 후에 그것의 부모를 선택
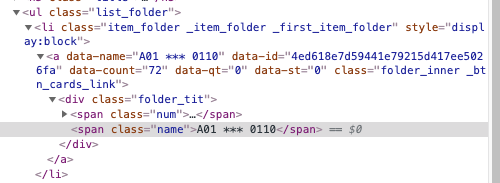
|
# 단어장 이름 |
네이버 단어장의 모든 단어를 파일로 저장
-
궁극적으로 셀레니움을 테스트했던 목적으로 완성된 코드이다.
|
from selenium import webdriver |
결과 및 평가
-
headless는 완벽하게 돌지 않아, 백그라운드 작업이 얼마나 가능할지는 봐야 할 듯
-
모든 작업이 실제 돌려봐야 알기 때문에, trial & error 디버깅이 쉽지 않아 프로그램 작성 시간이 오래 걸림
-
그럼에도 웹브라우저 작업을 자동화 할 수 있다는 장점
'기술' 카테고리의 다른 글
| Google CloudRun을 이용하여 키워드 기반 URL Shortcut 만들기 (빠른 사이트 접근) (0) | 2021.01.22 |
|---|---|
| 크롬 브라우저 자동화(Run JavaScript Extension) (0) | 2021.01.20 |
| Python PyDev IDE 개발툴 (0) | 2019.08.07 |
| Maven Profile + Exec Java (0) | 2019.08.07 |
| gRPC Protobuf 메시지 포맷/필드 보는 샘플 코드 (0) | 2019.08.07 |



