문서를 듣자!! 문서를 읽는 것은 집중력을 높여 이해도를 높여 주기도 하지만, 많은 문서를 볼 때는 오히려 음성으로 듣는 것이 낫기도 하다. 여기서는 Google Cloud TTS를 이용하여 Google Docs에 있는 내용을 음성으로 들어 본다. Google Cloud TTS의 예제이자, Google Docs 문서를 액세스하는 예제이기도 하다.
Permission
-
https://cloud.google.com/text-to-speech/docs/quickstart-protocol
-
특별한 Permission을 필요로 하지 않음
Service Account 생성 및 Key 생성 및 다운로드
-
tts-api라는 이름의 Service Account 생성 및 별 다른 Permission을 주지 않음
-
생성된 Account: tts-api@api-project-249965614499.iam.gserviceaccount.com
-
아래와 같이 JSON Key 생성
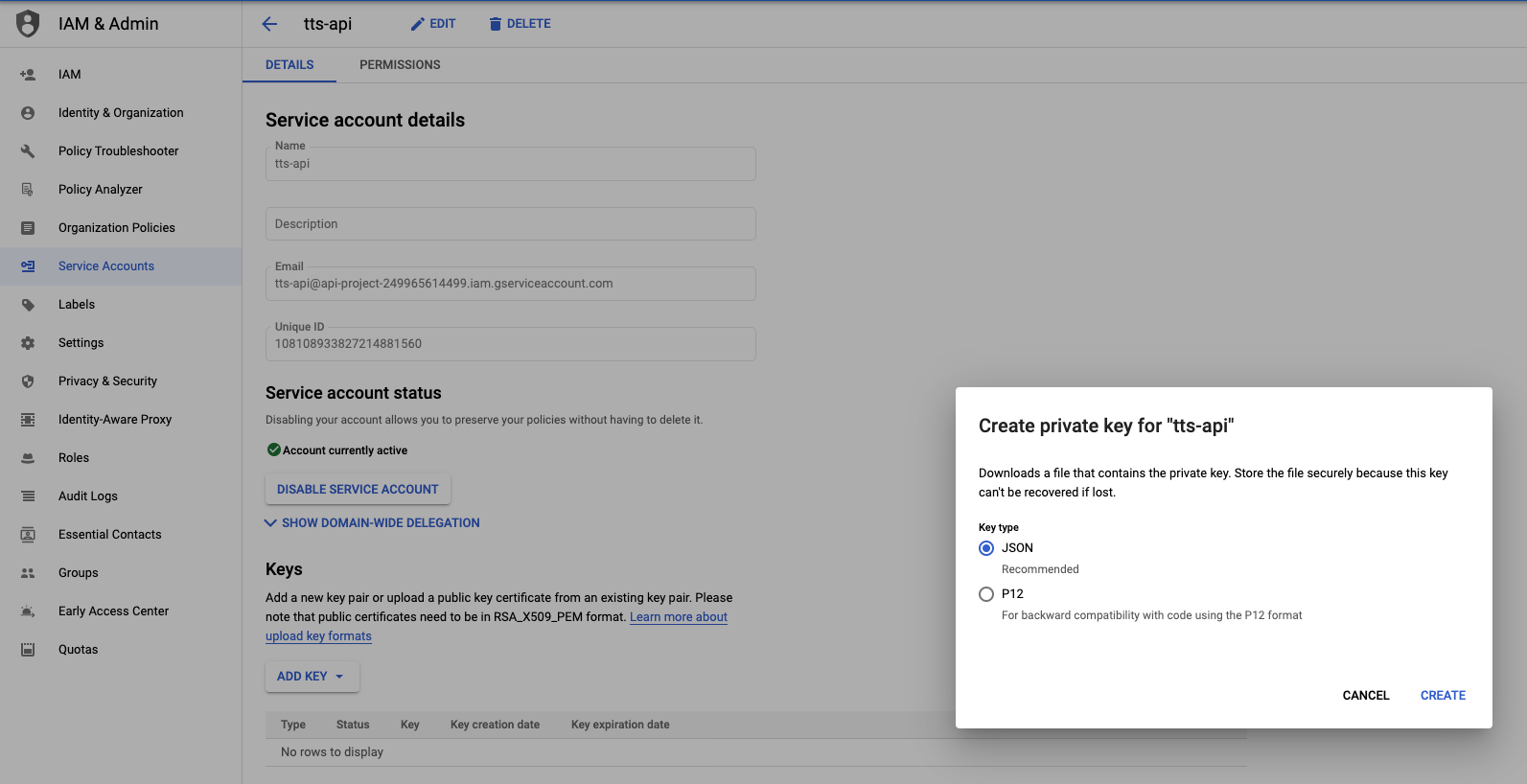
-
다음 받은 JSON 파일을 현재 디렉토리로 복사
|
$ mv ~/Downloads/api-project-249965614499-33c4f9f41469.json . |
액세스할 Google Docs 또는 Google Drive 폴더에 Service Account의 Read 권한 추가

필요한 구글 Python 라이브러리 패키지 설치
|
pip install google-api-python-client google-auth-httplib2 google-auth-oauthlib |
Google Docs를 읽어 JSON으로 출력하는 프로그램 작성
-
일단 테스트로 Google Docs의 JSON 구조를 확인하 위한 프로그램
-
dic.json 파일 생성
-
DOCUMENT_ID에 Google Docs의 ID (참고로 본 문서 사용)

|
from googleapiclient import discovery |
생성된 JSON 파일의 구조 확인
-
body/content 배열에 있는 paragraph가 각각의 문단
-
content에 텍스트 내용이 들어가고 한글은 Unicode로 escaping 됨
-
namedStyleType에 테스트의 Style
|
{ |
JSON에서 문단을 추출하는 프로그램
-
dic.json을 참고해서 다음과 같이 문단 추출 부분을 작성
|
... service = discovery.build('docs', 'v1', discoveryServiceUrl=DISCOVERY_DOC, credentials=credentials)
|
-
테이블 처리를 추가
|
... for sentence in result['body']['content']: |
-
테이블 테스트
|
컬럼1 |
컬럼2 |
컬럼3 |
|
로우2-1 |
로우2-2 |
로우2-3 |
|
로구3-1 |
로우3-2 |
로우3-3 |
|
문장인 경우에는 어떻게 하는 지 궁금합니다. 이어진 문장. 떨어진 문장. |
Flask Python 프로그램 작성
-
일단 Flask를 통해서 화면에 시각화 하는 프로그램. Google Docs 문서 ID를 URL 파라미터로 보내면 해당 결과를 HTML로 렌더링 해 준다
|
from flask import Flask, request, Response |
-
나중에 JavaScript에서 제어를 편하게 하기 위해서는 <h1> 등의 태그를 직접 사용하지 말고 <div>에 고유한 class 명을 넣어서 제어
|
styles = { |
Text To Speech API를 호출해서 Text를 읽기
-
Text를 음성으로 만들어 출력하는 부분은 브라우저에서 이루어져야 함
-
Google Cloud Text To Speech API 설치
|
$ pip install google-cloud-texttospeech |
-
Text를 보내면 TTS API 호출
|
@app.route("/speak/<encoding>") |
JavaScript 에서 음성 읽기를 키보드로 제어
-
Ctrl+> 키나 Ctrl+< 키를 통해 전진, 후진
-
Ctrl+? 키로 음성 읽기 중단
|
scripts = ''' |
HTML Body 생성
-
인코딩, 재생 속도 등을 제어할 수 있는 컨트롤 배치
|
html = '<html>\n' |

최종 소스
-
적절한 인증을 넣어 주어야 함
Cloud Run으로 실행
-
다음과 같이 스크립트를 만들어 실행
-
먼저 로컬에서 다음과 같은 스크립트를 이용하여 테스트
-
Dockerfile (5001 포트를 사용)
|
$ cat Dockerfile |
-
Google Docs ID 부분만을 사용하여 http://localhost:5001/<doc id>
|
$ cat 02.test_local.sh |
-
다음과 같이 Cloud Build 실행 (프로젝트 ID 등은 각자)
|
$ cat 01.build.sh |
-
다음과 같이 Cloud Run으로 실행
|
$ cat 03.deploy.sh |
'기술' 카테고리의 다른 글
| [Cygwin] Open SSH 설치하고 sshd 서비스로 등록하기 (0) | 2021.01.23 |
|---|---|
| Google CloudRun을 이용하여 키워드 기반 URL Shortcut 만들기 (빠른 사이트 접근) (0) | 2021.01.22 |
| 크롬 브라우저 자동화(Run JavaScript Extension) (0) | 2021.01.20 |
| Selenium을 이용한 웹사이트 크롤링 (0) | 2021.01.12 |
| Python PyDev IDE 개발툴 (0) | 2019.08.07 |



